Задачи прогнозирования построены на изменении неких данных во времени (продаж, спроса, поставок, ВВП, выбросов углерода, численности населения…) и проецировании этих изменений на будущее. К сожалению, выявленные на исторических данных, тренды могут нарушаться множеством непредвиденных обстоятельств. Так что данные в будущем могут существенно отличаться от произошедшего в прошлом. В этом и состоит проблема прогнозирования.
Однако, существуют методики (под названием экспоненциальное сглаживание), позволяющие не только попытаться предсказать будущее, но и выразить численно неопределенность всего, что связано с прогнозом. Численное выражение неопределенности с помощью создания интервалов прогнозирования поистине неоценимо, но часто игнорируется в прогностическом мире.
Скачать заметку в формате или , примеры в формате
Исходные данные
Допустим, вы фанат «Властелина Колец», и вот уже три года изготавливаете и торгуете мечами (рис. 1). Отобразим продажи графически (рис. 2). За три года спрос удвоился - может быть, это тренд? Мы вернемся к этой мысли чуть позже. На графике есть несколько пиков и спадов, что может быть признаком сезонности. В частности, пики приходятся на месяцы с номерами 12, 24 и 36, которые оказываются декабрями. Но может быть это лишь случайность? Давайте выясним.

Простое экспоненциальное сглаживание
Методы экспоненциального сглаживания основываются на прогнозировании будущего по данным из прошлого, где более новые наблюдения весят больше, чем старые. Такое взвешивание возможно благодаря константам сглаживания. Первый метод экспоненциального сглаживания, который мы опробуем, называется простым экспоненциальным сглаживанием (ПЭС, simple exponential smoothing, SES). Он использует лишь одну константу сглаживания.
При простом экспоненциальном сглаживании предполагается, что ваш временной ряд данных состоит из двух компонентов: уровня (или среднего) и некоей погрешности вокруг этого значения. Нет никакого тренда или сезонных колебаний - есть просто уровень, вокруг которого колеблется спрос, тут и там окруженный небольшими погрешностями. Отдавая предпочтение более новым наблюдениям, ПЭС может явиться причиной сдвигов этого уровня. Говоря языком формул,
Спрос в момент времени t = уровень + случайная погрешность около уровня в момент времени t
Так как же найти приблизительное значение уровня? Если принять все временные значения как имеющие одинаковую ценность, то следует просто вычислить их среднее значение. Однако, это плохая идея. Следует дать больший вес недавним наблюдениям.
Создадим несколько уровней. Рассчитаем исходный уровень в первый год:
уровень 0 = среднее значение спроса за первый год (месяцы 1-12)
Для спроса на мечи он равен 163. Мы используем уровень 0 (163) как прогноз спроса на месяц 1. Спрос в месяц 1 равен 165, то есть он на 2 меча выше уровня 0 . Стоит обновить приближение исходного уровня. Уравнение простого экспоненциального сглаживания:
уровень 1 = уровень 0 + несколько процентов × (спрос 1 – уровень 0)
уровень 2 = уровень 1 + несколько процентов × (спрос 2 – уровень 1)
И т.д. «Несколько процентов» - называется константой сглаживания, и обозначается альфой. Это может быть любое число от 0 до 100% (от 0 до 1). Выбирать значение альфы вы научитесь позже. В общем случае значение для разных моментов времени:
Уровень текущий период = уровень предыдущий период +
альфа × (спрос текущий период – уровень предыдущий период)
Будущий спрос равен последнему вычисленному уровню (рис. 3). Поскольку вы не знаете, чему равна альфа, установите для начала в ячейке С2 значение 0,5. После того, как модель будет построена, найдите такую альфа, чтобы сумма квадратов ошибки – Е2 (или стандартное отклонение – F2) были минимальны. Для этого запустите опцию Поиск решения . Для этого пройдите по меню ДАННЫЕ –> Поиск решения , и установите в окне Параметры поиска решения требуемые значения (рис. 4). Чтобы отразить результаты прогноза на диаграмме, для начала выберите диапазон А6:В41, и постройте простую линейную диаграмму. Далее кликните на диаграмме правой кнопкой мыши, выберите опцию Выбрать данные. В открывшемся окне создайте второй ряд и вставьте в него предсказания из диапазона А42:В53 (рис. 5).



Возможно, у вас есть тренд
Чтобы проверить это предположение достаточно подогнать линейную регрессию под данные спроса и выполнить тест на соответствие критерию Стьюдента на подъеме этой линии тренда (как в ). Если уклон линии ненулевой и статистически значимый (в проверке по критерию Стьюдента величина р менее 0,05), у данных есть тренд (рис. 6).

Мы воспользовались функцией ЛИНЕЙН, которая возвращает 10 описательных статистик (если вы ранее не пользовались этой функцией, рекомендую ) и функцией ИНДЕКС, которая позволяет «вытащить» только три требуемые статистики, а не весь набор. Получилось, что наклон равен 2,54, и он значим, так как тест Стьюдента показал, 0,000000012 существенно меньше 0,05. Итак, тренд есть, и осталось включить его в прогноз.
Экспоненциальное сглаживание Холта с корректировкой тренда
Часто оно называется двойным экспоненциальным сглаживанием, потому что имеет не один параметр сглаживания - альфа, а два. Если у временной последовательности линейный тренд, то:
спрос за время t = уровень + t × тренд + случайное отклонение уровня в момент времени t
Экспоненциальное сглаживание Холта с корректировкой тренда имеет два новых уравнения, одно - для уровня по мере его продвижения во времени, а другое - тренд. Уравнение уровня содержит сглаживающий параметр альфа, а уравнение тренда – гамма. Вот как выглядит новое уравнение уровня:
уровень 1 = уровень 0 + тренд 0 + альфа × (спрос 1 – (уровень 0 + тренд 0))
Обратите внимание, что уровень 0 + тренд 0 - это просто одношаговый прогноз от исходных значений к месяцу 1, поэтому спрос 1 – (уровень 0 + тренд 0) - это одношаговое отклонение. Таким образом, основное уравнение приближения уровня будет следующим:
уровень текущий период = уровень предыдущий период + тренд предыдущий период + альфа × (спрос текущий период – (уровень предыдущий период) + тренд предыдущий период))
Уравнение обновления тренда:
тренд текущий период = тренд предыдущий период + гамма × альфа × (спрос текущий период – (уровень предыдущий период) + тренд предыдущий период))
Холтовское сглаживание в Excel аналогично простому сглаживанию (рис. 7), и, как и выше, цель – найти два коэффициента, минимизируя сумму квадратов ошибок (рис. 8). Чтобы получить исходные значения уровня и тренда (в ячейках С5 и D5 на рис. 7), постройте график за первые 18 месяцев продаж и добавьте к нему линию тренда с уравнением. Исходное значение тренда 0,8369 и исходный уровень 155,88 занесите в ячейки С5 и D5. Прогнозные данные можно представить графически (рис. 9).

Рис. 7. Экспоненциальное сглаживание Холта с корректировкой тренда; чтобы увеличить изображение кликните на нем правой кнопкой мыши и выберите Открыть картинку в новой вкладке


Выявление закономерностей в данных
Есть способ испытать прогностическую модель на прочность - сравнить погрешности сами с собой, сдвинутыми на шаг (или несколько шагов). Если отклонения случайны, то улучшить модель нельзя. Однако, возможно, в данных о спросе есть сезонный фактор. Концепция погрешности, коррелирующей с собственной версией за другой период, называется автокорреляцией (подробнее об автокорреляции см. ). Чтобы рассчитать автокорреляцию, начните с данных об ошибке прогноза за каждый период (столбец F на рис. 7 переносим в столбец В на рис. 10). Далее определите среднюю ошибку прогноза (рис. 10, ячейка В39; формула в ячейке: =СРЗНАЧ(B3:B38)). В столбце С рассчитайте отклонение ошибки прогноза от среднего; формула в ячейке С3: =B3-B$39. Далее последовательно сдвигайте столбец С на столбец вправо и строку вниз. Формулы в ячейках D39: =СУММПРОИЗВ($C3:$C38;D3:D38), D41: =D39/$C39, D42: =2/КОРЕНЬ(36), D43: =-2/КОРЕНЬ(36).

Что может значить для одного из столбцов D:O «синхронное движение» со столбцом С. Например, если столбцы С и D синхронны, то число, отрицательное в одном из них, должно быть отрицательным и в другом, положительное в одном, положительное – в другом. Это означает, что сумма произведений двух столбцов будет значительной (отличия накапливаются). Или, что тоже самое, чем ближе значение в диапазоне D41:О41 к нулю, тем ниже корреляция столбца (соответственно от D до О) со столбцом С (рис. 11).

Одна автокорреляция выше критического значения. Погрешность, сдвинутая на год, коррелирует сама с собой. Это означает 12-месячный сезонный цикл. И это неудивительно. Если вы посмотрите на график спроса (рис. 2), то окажется, что есть пики спроса на каждое Рождество и провалы в апреле-мае. Рассмотрим технику прогнозирования, учитывающую сезонность.
Мультипликативное экспоненциальное сглаживание Холта-Винтерса
Метод называется мультипликативным (от multiplicate - умножать), поскольку использует умножение для учета сезонности:
Спрос в момент t = (уровень + t × тренд) × сезонная поправка для момента t × все оставшиеся нерегулярные поправки, которые мы не можем учесть
Сглаживание Холта-Винтерса также называют тройным экспоненциальным сглаживанием, потому что у него три сглаживающих параметра (альфа, гамма и сезонный фактор – дельта). Например, если имеется 12-месячный сезонный цикл:
Прогноз на месяц 39 = (уровень 36 + 3 × тренд 36) х сезонность 27
Анализируя данные, необходимо выяснить, что в серии данных является трендом, а что - сезонностью. Чтобы выполнить вычисления по методу Холта-Винтерса, необходимо:
- Сгладить исторические данные методом скользящего среднего.
- Сравнить сглаженную версию временного ряда данных с оригиналом, чтобы получить приблизительную оценку сезонности.
- Получить новые данные без сезонного компонента.
- Найти приближения уровня и тренда на основе этих новых данных.
Начните с исходных данных (столбцы А и В на рис. 12) и добавьте столбец С со сглаженными значениями на основе скользящего среднего. Так как сезонность имеет 12-месячные циклы, имеет смысл использовать среднее за 12 месяцев. С этим средним есть небольшая проблема. 12 – четное число. Если вы сглаживаете спрос за месяц 7, стоит ли считать его средним спросом с 1-го по 12-й месяц или со 2-го по 13-й? Чтобы справиться с этим затруднением, нужно сгладить спрос с помощью «скользящего среднего 2×12». Т.е., взять половину от двух средних с 1 по 12-й месяц и со 2 по 13. Формула в ячейке С8: =(СРЗНАЧ(B3:B14)+СРЗНАЧ(B2:B13))/2.

Сглаженные данных для месяцев 1–6 и 31–36 получить нельзя, так как не хватает предыдущих и последующих периодов. Для наглядности исходные и сглаженные данные можно отразить на диаграмме (рис. 13).

Теперь в столбце D разделите оригинальную величину на сглаженную и получите приблизительное значение сезонной поправки (столбец D на рис. 12). Формула в ячейке D8: =B8/C8. Обратите внимание на всплески в 20% выше нормального спроса в месяцах 12 и 24 (декабрь), в то время как весной наблюдаются провалы. Эта техника сглаживания дала вам две точечные оценки для каждого месяца (всего 24 месяца). В столбце Е найдено среднее значение этих двух факторов. Формула в ячейке Е1: =СРЗНАЧ(D14;D26). Для наглядности уровень сезонных колебаний можно представить графически (рис. 14).

Теперь можно получить данные, скорректированные на сезонные колебания. Формула в ячейке G1: =B2/E2. Постройте график на основе данных столбца G, дополните его линией тренда, выведите уравнение тренда на диаграмму (рис. 15), и используйте коэффициенты в последующих расчетах.

Сформируйте новый лист, как показано на рис. 16. Значения в диапазон Е5:Е16 подставьте с рис. 12 области Е2:Е13. Значения С16 и D16 возьмите из уравнения линии тренда на рис. 15. Значения констант сглаживания установите для начала на отметке 0,5. Растяните значения в строке 17 на диапазон месяцев с 1 по 36. Запустите Поиск решения для оптимизации коэффициентов сглаживания (рис. 18). Формула в ячейке В53: =(C$52+(A53-A$52)*D$52)*E41.


Теперь в сделанном прогнозе нужно проверить автокорреляции (рис. 18). Так как все значения расположились между верхней и нижней границами, вы понимаете, что модель неплохо поработала над пониманием структуры значений спроса.

Построение доверительного интервала прогноза
Итак, у нас есть вполне рабочий прогноз. Как установить верхние и нижние границы, которые можно использовать для построения реалистичных предположений? В этом вам поможет симуляция Монте-Карло, с которой вы уже встречались в (см. также ). Смысл заключается в том, чтобы сгенерировать будущие сценарии поведения спроса и определить группу, в которую попадают 95% из них.
Удалите с листа Excel прогноз из ячеек В53:В64 (см. рис. 17). Вы запишете туда спрос на основе симуляции. Последнюю можно сгенерировать с помощью функции НОРМОБР. Для будущих месяцев вам достаточно снабдить ее средним (0), стандартным распределением (10,37 из ячейки $Н$2) и случайным числом от 0 до 1. Функция вернет отклонение с вероятностью, соответствующей колоколообразной кривой. Поместите симуляцию одношаговой погрешности в ячейку G53: =НОРМОБР(СЛЧИС();0;H$2). Растянув эту формулу вниз до G64, и вы получите симуляции ошибки прогноза для 12 месяцев одношагового прогноза (рис. 19). Ваши значения симуляций будут отличаться от приведенных на рисунке (на то она и симуляция!).

С погрешностью прогноза у вас есть все, что нужно для обновления уровня, тренда и сезонного коэффициента. Так что выделите ячейки C52:F52 и растяните их до строки 64. В результате у вас имеются симулированная ошибка прогноза и сам прогноз. Идя от обратного, можно спрогнозировать значения спроса. Вставьте в ячейку В53 формулу: =F53+G53 и растяните ее до В64 (рис. 20, диапазон В53:F64). Теперь вы можете нажимать на кнопку F9, каждый раз обновляя прогноз. Разместите результаты 1000 симуляций в ячейках А71:L1070, каждый раз транспонируя значения из диапазона В53:В64 в диапазон А71:L71, A72:L72, … A1070:L1070. Если вас это напрягает напишите код VBA.

Теперь у вас есть по 1000 сценариев на каждый месяц, и вы можете использовать функцию ПЕРСЕНТИЛЬ, чтобы получить верхние и нижние границы в середине 95%-ного доверительно интервала. В ячейке А66 формула: =ПЕРСЕНТИЛЬ(A71:A1070;0,975), а в ячейке А67: =ПЕРСЕНТИЛЬ(A71:A1070;0,025).
Как обычно, для наглядности данные можно представить в графическом виде (рис. 21).

На графике есть два интересных момента:
- Погрешность со временем становится шире. В этом есть смысл. Неуверенность накапливается с каждым месяцем.
- Точно так же погрешность растет и в частях, приходящихся на периоды сезонного повышения спроса. С последующим его падением погрешность сжимается.
Написано по материалам книги Джона Формана . – М.: Альпина Паблишер, 2016. – С. 329–381
02.04.2011 – Стремление человека приподнять завесу грядущего и предвидеть ход событий имеет такую же длинную историю, как и его попытки, понять окружающий мир. Очевидно, что в основе интереса к прогнозу лежат достаточно сильные жизненные мотивы (теоретические и практические). Прогноз выступает в качестве важнейшего метода проверки научных теорий и гипотез. Способность предвидеть будущее является неотъемлемой стороной сознания, без которой была бы невозможна сама человеческая жизнь.
Понятие “прогнозирование” (от греч. prognosis – предвидение, предсказание) означает процесс разработки вероятностного суждения о состоянии какого-либо явления или процесса в будущем, это познание того, чего еще нет, но что может наступить в ближайшее или отдаленное время.
Прогноз по своему содержанию более сложен, чем предсказание. Он, с одной стороны, отражает наиболее вероятное состояние объекта, а с другой – определяет пути и средства достижения желаемого результата. На основе полученной прогнозным путем информации по достижению желаемой цели, принимаются определенные решения.
Необходимо отметить, что динамика экономических процессов в современных условиях отличается нестабильностью и неопределенностью, что затрудняет применение традиционных методов прогнозирования.
Модели экспоненциального сглаживания и прогнозирования относятся к классу адаптивных методов прогнозирования, основной характеристикой которых является способность непрерывно учитывать эволюцию динамических характеристик изучаемых процессов, подстраиваться под эту динамику, придавая, в частности, тем больший вес и тем более высокую информационную ценность имеющимся наблюдениям, чем ближе они расположены к текущему моменту времени. Смысл термина состоит в том, что адаптивное прогнозирование позволяет обновлять прогнозы с минимальной задержкой и с помощью относительно несложных математических процедур.
Метод экспоненциального сглаживания был независимо открыт Брауном (Brown R.G. Statistical forecasting for inventory control, 1959) и Хольтом (Holt C.C. Forecasting Seasonal and Trends by Exponentially Weighted Moving Averages, 1957). Экспоненциальное сглаживание, как и метод скользящих средних, для прогноза использует прошлые значения временного ряда.
Сущность метода экспоненциального сглаживания заключается в том, что временной ряд сглаживается с помощью взвешенной скользящей средней, в которой веса подчиняются экспоненциальному закону. Взвешенная скользящая средняя с экспоненциально распределенными весами характеризует значение процесса на конце интервала сглаживания, то есть является средней характеристикой последних уровней ряда. Именно это свойство и используется для прогнозирования.
Обычное экспоненциальное сглаживание применяется в случае отсутствия в данных тренда или сезонности. В этом случае прогноз является взвешенной средней всех доступных предыдущих значений ряда; веса при этом со временем геометрически убывают по мере продвижения в прошлое (назад). Поэтому (в отличие от метода скользящего среднего) здесь нет точки, на которой веса обрываются, то есть зануляются. Прагматически ясная модель простого экспоненциального сглаживания может быть записана следующим (по представленной ссылке можно скачать все формулы статьи):
Покажем экспоненциальный характер убывания весов значений временного ряда – от текущего к предыдущему, от предыдущего к пред–предыдущему и так далее:
Если формула применяется
рекурсивно, то каждое новое сглаженное значение (которое является также
прогнозом) вычисляется как взвешенное среднее текущего наблюдения и сглаженного
ряда. Очевидно, что результат сглаживания зависит от параметра адаптации альфа
.
Его можно интерпретировать как коэффициент дисконтирования, характеризующий
меру девальвации данных за единицу времени. Причем влияние данных на прогноз
экспоненциально убывает с “возрастом” данных. Зависимость влияния данных на
прогноз при разных коэффициентах альфа
приведена на рисунке 1.

Рисунок 1. Зависимость влияния данных на прогноз при разных коэффициентах адаптации
Следует заметить, что значение сглаживающего параметра не может равняться 0 или 1, так как в этом случае сама идея экспоненциального сглаживания отвергается. Так, если альфа равняется 1, то прогнозное значение F t+1 совпадает с текущим значением ряда Хt , при этом экспоненциальная модель стремится к самой простой “наивной” модели, то есть в этом случае прогнозирование является абсолютно тривиальным процессом. Если альфа равняется 0, то начальное прогнозное значение F 0 (initial value ) одновременно будет являться прогнозом для всех последующих моментов ряда, то есть прогноз в этом случае будет выглядеть в виде обычной горизонтальной линии.
Тем не менее, рассмотрим варианты сглаживающего параметра, близкие к 1 или 0. Так, если альфа близко к 1, то предыдущие наблюдения временного ряда практически полностью игнорируются. В случае если альфа близко к 0, то игнорируются уже текущие наблюдения. Значения альфа между 0 и 1 дают промежуточные результаты. По мнению ряда авторов, оптимальное значение альфа находится в пределах от 0,05 до 0,30. Однако иногда альфа , большее 0,30, дает лучший прогноз.
В целом лучше оценивать оптимальное альфа по исходным данным (при помощи поиска по сетке), а не использовать искусственные рекомендации. Тем не менее, в случае если значение альфа , превышающее 0,3, минимизирует ряд специальных критериев, то это указывает на то, что другая техника прогнозирования (с применением тренда или сезонности) способна обеспечить еще более точные результаты. Для нахождения оптимального значения альфа (то есть минимизации специальных критериев) используется квазиньютоновский алгоритм максимизации правдоподобия (вероятности), который эффективнее обычного перебора на сетке.
Перепишем уравнение (1) в виде альтернативного варианта, позволяющего оценить, как модель экспоненциального сглаживания “обучается” на своих прошлых ошибках:
Из уравнения (3) ярко видно, что прогноз на период t+1 подлежит изменению в сторону увеличения, в случае превышения фактического значения временного ряда в период t над прогнозным значением, и, наоборот, прогноз на период t+1 должен быть уменьшен, если Х t меньше, чем F t .
Отметим, что при использовании методов экспоненциального сглаживания важным вопросом всегда является определение начальных условий (начального прогнозного значения F 0 ). Процесс выбора начального значения сглаженного ряда называется инициализацией (initializing ), или, иначе, “разогревом” (“warming up ”) модели. Дело в том, что начальное значение сглаженного процесса может существенным образом повлиять на прогноз для последующих наблюдений. С другой стороны, влияние выбора уменьшается с длиной ряда и становится некритичным при очень большом числе наблюдений. Браун впервые предложил использовать в качестве стартового значения среднее динамического ряда. Другие авторы предлагают использовать в качестве начального прогноза первое фактическое значение временного ряда.
В середине прошлого века Хольт предложил расширить модель простого экспоненциального сглаживания за счет включения в нее фактора роста (growth factor ), или иначе тренда (trend factor ). В результате модель Хольта может быть записана следующим образом:
Данный метод позволяет учесть присутствие в данных линейного тренда. Позднее были предложены другие виды трендов: экспоненциальный, демпфированный и др.
Винтерс предложил усовершенствовать модель Хольта с точки зрения возможности описания влияния сезонных факторов (Winters P.R. Forecasting Sales by Exponentially Weighted Moving Averages, 1960).
В частности, он далее расширил модель Хольта за счет включения в нее дополнительного уравнения, описывающего поведение сезонной компоненты (составляющей). Система уравнений модели Винтерса выглядит следующим образом:
Дробь в первом уравнении служит для исключения сезонности из исходного ряда. После исключения сезонности (по методу сезонной декомпозиции Census I ) алгоритм работает с “чистыми” данными, в которых нет сезонных колебаний. Появляются они уже в самом финальном прогнозе (15), когда “чистый” прогноз, посчитанный почти по методу Хольта, умножается на сезонную компоненту (индекс сезонности ).
к.э.н., директор по науке и развитию ЗАО "КИС"
Метод экспоненциального сглаживания
Освоение новых и анализ известных управленческих технологий, которые позволяют повысить эффективность управления бизнесом, становится особенно актуальным для российских предприятий в настоящее время. Один из наиболее популярных инструментов - система бюджетирования, которая базируется на формировании бюджета предприятия с последующим контролем исполнения. Бюджет представляет собой сбалансированные краткосрочные коммерческие, производственные, финансовые и хозяйственные планы развития организации. Бюджет предприятия содержит целевые показатели, которые рассчитываются на основании прогнозных данных. Наиболее значимым прогнозом при составлении бюджета для любого предприятия является прогноз продаж. В предыдущих статьях был проведен анализ аддитивной и мультипликативной модели и рассчитан прогнозный объем продаж на следующие периоды.
При анализе временных рядов использовался метод скользящей средней, в котором все данные независимо от периода их возникновения являются равноправными. Существует другой способ, в котором данным приписываются веса, более поздним данным придается больший вес, чем более ранним.
Метод экспоненциального сглаживания в отличие от метода скользящих средних еще и может быть использован для краткосрочных прогнозов будущей тенденции на один период вперед и автоматически корректирует любой прогноз в свете различий между фактическим и спрогнозированным результатом. Именно поэтому метод обладает явным преимуществом над ранее рассмотренным.
Название метода происходит из того факта, что при его применении получаются экспоненциально взвешенные скользящие средние по всему временному ряду. При экспоненциальном сглаживании учитываются все предшествующие наблюдения - предыдущее учитывается с максимальным весом, предшествующее ему - с несколько меньшим, самое ранее наблюдение влияет на результат с минимальным статистическим весом.
Алгоритм расчета экспоненциально сглаженных значений в любой точке ряда i основан на трех величинах :
фактическое значение Ai в данной точке ряда i,
прогноз в точке ряда Fi
некоторый заранее заданный коэффициент сглаживания W, постоянный по всему ряду.
Новый прогноз можно записать формулой:
Расчет экспоненциально сглаженных значений
При практическом использовании метода экспоненциального сглаживания возникает две проблемы: выбор коэффициента сглаживания (W), который в значительной степени влияет на результаты и определение начального условия (Fi). С одной стороны, для сглаживания случайных отклонений величину нужно уменьшать. С другой стороны, для увеличения веса новых измерений нужно увеличивать.
Хотя, в принципе, W может принимать любые значения из диапазона 0 < W < 1, обычно ограничиваются интервалом от 0,2 до 0,5. При высоких значениях коэффициента сглаживания в большей степени учитываются мгновенные текущие наблюдения отклика (для динамично развивающихся фирм) и, наоборот, при низких его значениях сглаженная величина определяется в большей степени прошлой тенденцией развития, нежели текущим состоянием отклика системы (в условиях стабильного развития рынка).
Выбор коэффициента постоянной сглаживания является субъективным. Аналитики большинства фирм при обработке рядов используют свои традиционные значения W. Так, по опубликованным данным в аналитическом отделе Kodak, традиционно используют значение 0,38, а на фирме Ford Motors - 0,28 или 0,3.
Ручной расчет экспоненциального сглаживания требует крайне большого объема монотонной работы. На примере рассчитаем прогнозный объем на 13 квартал, если имеются данные объема продаж за последние 12 кварталов, используя метод простого экспоненциального сглаживания.
Предположим, что на первый квартал прогноз продаж составил 3. И пусть коэффициент сглаживания W =0,8.
Заполним в таблице третий столбец, подставляя для каждого последующего квартала значение предыдущего по формуле:
Для 2 квартала F2 =0,8*4 (1-0,8)*3 =3,8
Для 3 квартала F3 =0,8*6 (1-0,8)*3,8 =5,6
Аналогично, рассчитывается сглаженное значение для коэффициента 0,5 и 0,33.
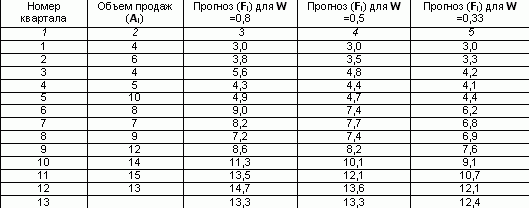
Расчет прогноза
объема
продаж
Прогноз объема продаж при W = 0.8 на 13 квартал составил 13.3 тыс.руб.
Эти данные можно представить в графической форме:
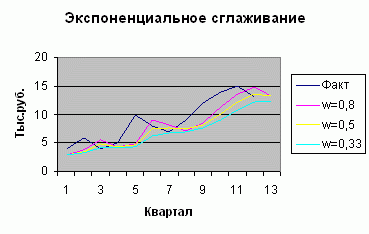
Экспоненциальное сглаживание
Экспоненциальное сглаживание - способ сглаживания временных рядов, вычислительная процедура которого включает обработку всех предыдущих наблюдений, при этом учитывается устаревание информации по мере удаления от прогнозного периода. Иначе говоря, чем "старше" наблюдение, тем меньше оно должно влиять на величину прогнозной оценки. Идея экспоненциального сглаживания состоит в том, что по мере "старения" соответствующим наблюдениям придаются убывающие веса.
Данный метод прогнозирования считается весьма эффективным и падежным. Основные достоинства метода состоят в возможности учета весов исходной информации, в простоте вычислительных операций, в гибкости описания различных динамик процессов. Метод экспоненциального сглаживания дает возможность получить оценку параметров тренда, характеризующих не средний уровень процесса, а тенденцию, сложившуюся к моменту последнего наблюдения. Наибольшее применение метод нашел для реализации среднесрочных прогнозов. Для метода экспоненциального сглаживания основным моментом является выбор параметра сглаживания (сглаживающей константы) и начальных условий.
Простое экспоненциальное сглаживание временных рядов, содержащих тренд, приводит к систематической ошибке, связанной с отставанием сглаженных значений от фактических уровней временного ряда. Для учета тренда в нестационарных рядах применяется специальное двухпараметрическое линейное экспоненциальное сглаживание. В отличие от простого экспоненциального сглаживания с одной сглаживающей константой (параметром) данная процедура сглаживает одновременно случайные возмущения и тренд с использованием двух различных констант (параметров). Двухпараметрический метод сглаживания (метод Хольта) включает два уравнения. Первое предназначено для сглаживания наблюденных значений, а второе -для сглаживания тренда:
где I - 2, 3, 4 - периоды сглаживания; 5, - сглаженная величина на период £; У, - фактическое значение уровня на период 1 5, 1 - сглаженное значение на период Ь-Ьг- сглаженное значение тренда на период 1 - сглаженное значение на период I- 1; А и В - сглаживающие константы (числа между 0 и 1).
Сглаживающие константы А и В характеризуют фактор взвешивания наблюдений. Обычно Л, В < 0,3. Так как (1 - А) < 1, (1 - В) < 1, то они убывают по экспоненциальному закону по мере удаления наблюдения от текущего периода I. Отсюда данная процедура получила название экспоненциально сглаживания.
Уравнение добавляется в общую процедуру для сглаживания тренда. Каждая новая оценка тренда получается как взвешенная сумма разности между последними двумя сглаженными значениями (текущая оценка тренда) и предыдущей сглаженной оценки. Данное уравнение позволяет существенно сократить влияние случайных возмущений на тренд с течением времени.
Прогнозирование с использованием экспоненциального сглаживания подобно процедуре "наивного" прогнозирования, когда прогнозная оценка на завтра полагается равной сегодняшнему значению. В данном случае в качестве прогноза на один период вперед рассматривается сглаженная величина на текущий период плюс текущее сглаженное значение тренда:
Данную процедуру можно использовать для прогнозирования на любое число периодов, на пример на т периодов:
Процедура прогнозирования начинается с того, что сглаженная величина 51 полагается равной первому наблюдению У, т.е. 5, = У,.
Возникает проблема определения начального значения тренда 6]. Существуют два способа оценки Ьх.
Способ 1. Положим Ьх = 0. Такой подход хорошо работает в случае длинного исходного временного ряда. Тогда сглаженный тренд за небольшое число периодов приблизится к фактическому значению тренда.
Способ 2. Можно получить более точную оценку 6, используя первые пять (или более) наблюдений временного ряда. На их основе гю методу наименьших квадратов решается уравнение У(= а + Ь х г. Величина Ь берется в качестве начального значения тренда.
Простая и логически ясная модель временного ряда имеет следующий вид:
где b - константа, а ε - случайная ошибка. Константа b относительно стабильна на каждом временном интервале, но может также медленно изменяться со временем. Один из интуитивно ясных способов выделения значения b из данных состоит в том, чтобы использовать сглаживание скользящим средним, в котором последним наблюдениям приписываются большие веса, чем предпоследним, предпоследним большие веса, чем пред- предпоследним, и т.д. Простое экспоненциальное сглаживание именно так и построено. Здесь более старым наблюдениям приписываются экспоненциально убывающие веса, при этом, в отличие от скользящего среднего, учитываются все предшествующие наблюдения ряда, а не только те, которые попали в определенное окно. Точная формула простого экспоненциального сглаживания имеет вид:
Когда эта формула применяется рекурсивно, каждое новое сглаженное значение (которое является также прогнозом) вычисляется как взвешенное среднее текущего наблюдения и сглаженного ряда. Очевидно, результат сглаживания зависит от параметра α . Если α равен 1, то предыдущие наблюдения полностью игнорируются. Если а равен 0, то игнорируются текущие наблюдения. Значения α между 0 и 1 дают промежуточные результаты. Эмпирические исследования показали, что простое экспоненциальное сглаживание весьма часто дает достаточно точный прогноз.
На практике обычно рекомендуется брать α меньше 0,30. Однако выбор а больше 0,30 иногда дает более точный прогноз. Это значит, что лучше все же оценивать оптимальное значение α по реальным данным, чем использовать общие рекомендации.
На практике оптимальный параметр сглаживания часто ищется с использованием процедуры поиска на сетке. Возможный диапазон значений параметра разбивается сеткой с определенным шагом. Например, рассматривается сетка значений от α =0,1 до α = 0,9 с шагом 0,1. Затем выбирается такое значение α , для которого сумма квадратов (или средних квадратов) остатков (наблюдаемые значения минус прогнозы на шаг вперед) является минимальной.
Microsoft Excel располагает функцией Экспоненциальное сглаживание (Exponential Smoothing), которая обычно используется для сглаживания уровней эмпирического временного ряда на основе метода простого экспоненциального сглаживания. Для вызова этой функции необходимо на панели меню выбрать команду Tools - Data Analysis. На экране раскроется окно Data Analysis, в котором следует выбрать значение Экспоненциальное сглаживание. В результате появится диалоговое окно Экспоненциальное сглаживание , представленное на рис. 11.5.

В диалоговом окне Exponential Smoothing задаются практически те же параметры, го и в рассмотренном выше диалоговом окне Moving Average.
1. Input Range (Входные данные) - в это поле вводится диапазон ячеек, содержащих значения исследуемого параметра.
2. Labels (Метки) - данный флажок опции устанавливается в том случае, если первая строка (столбец) во входном диапазоне содержит заголовок. Если заголовок отсутствует, флажок следует сбросить. В этом случае для данных выходного диапазона будут автоматически созданы стандартные названия.
3. Damping factor (Фактор затухания) - в это поле вводится значение выбранного коэффициента экспоненциального сглаживания α . По умолчанию принимается значение α = 0,3.
4. Output options (Параметры вывода) - в этой группе, помимо указания диапазона ячеек для выходных данных в поле Output Range (Выходной диапазон), можно также потребовать автоматически построить график, для чего необходимо установить флажок опции Chart Output (Вывод графика), и рассчитать стандартные погрешности, для чего нужно установить флажок опции Standart Errors (Стандартные погрешности).
Воспользуемся функцией Экспоненциальное сглаживание для повторного решения рассмотренной выше задачи, но уже с помощью метода простого экспоненциального сглаживания. Выбранные значения параметров сглаживания представлены на рис. 11.5. На рис. 11.6 показаны рассчитанные показатели, а на рис. 11.7 - построенные графики.

