В случае, если совокупность разбита на группы по изучаемому признаку, то для данной совокупности могут быть исчислены следующие виды дисперсии: общая, групповые (внутригрупповые), средняя из групповых (средняя из внутригрупповых), межгрупповая.
Первоначально рассчитывает коэффициент детерминации, который показывает какую часть общей вариации изучаемого признака составляет вариация межгрупповая, т.е. обусловленная группировочным признаком:
Эмпирическое корреляционное отношение характеризует тесноту связи между признаками группировочным (факторным) и результативным.
Эмпирическое корреляционное отношение может принимать значения от 0 до 1.
Для оценки тесноты связи на основе показателя эмпирического корреляционного отношения можно воспользоваться соотношениями Чеддока:
Пример 4. Имеются следующие данные о выполнении работ проектно-изыскательскими организациями разной формы собственности:
Определить:
1) общую дисперсию;
2) групповые дисперсии;
3) среднюю из групповых дисперсий;
4) межгрупповую дисперсию;
5) общую дисперсию на основе правила сложения дисперсий;
6) коэффициент детерминации и эмпирическое корреляционное отношение.
Сделайте выводы.
Решение:
1. Определим средний объём выполнения работ предприятий двух форм собственности:
Рассчитаем общую дисперсию:
![]()
2. Определим групповые средние:
![]() млн руб.;
млн руб.;
![]() млн руб.
млн руб.
Групповые дисперсии:
![]() ;
;
3. Рассчитаем среднюю из групповых дисперсий:
4. Определим межгрупповую дисперсию:
5. Рассчитаем общую дисперсию на основе правила сложения дисперсий:
6. Определим коэффициент детерминации:
![]() .
.
Таким образом, объём работ, выполненных проектно-изыскательскими организациями на 22% зависит от формы собственности предприятий.
Эмпирическое корреляционное отношение рассчитываем по формуле
![]() .
.
Величина рассчитанного показателя свидетельствует о том, что зависимость объема работ от формы собственности предприятия невелика.
Пример 5. В результате обследования технологической дисциплины производственных участков получены следующие данные:
Определите коэффициент детерминации
Дисперсия случайной величины является мерой разброса значений этой величины. Малая дисперсия означает, что значения сгруппированы близко друг к другу. Большая дисперсия свидетельствует о сильном разбросе значений. Понятие дисперсии случайной величины применяется в статистике. Например, если сравнить дисперсию значений двух величин (таких как результаты наблюдений за пациентами мужского и женского пола), можно проверить значимость некоторой переменной. Также дисперсия используется при построении статистических моделей, так как малая дисперсия может быть признаком того, что вы чрезмерно подгоняете значения.Шаги
Вычисление дисперсии выборки
-
Запишите значения выборки. В большинстве случаев статистикам доступны только выборки определенных генеральных совокупностей. Например, как правило, статистики не анализируют расходы на содержание совокупности всех автомобилей в России – они анализируют случайную выборку из нескольких тысяч автомобилей. Такая выборка поможет определить средние расходы на автомобиль, но, скорее всего, полученное значение будет далеко от реального.
- Например, проанализируем количество булочек, проданных в кафе за 6 дней, взятых в случайном порядке. Выборка имеет следующий вид: 17, 15, 23, 7, 9, 13. Это выборка, а не совокупность, потому что у нас нет данных о проданных булочках за каждый день работы кафе.
- Если вам дана совокупность, а не выборка значений, перейдите к следующему разделу.
-
Запишите формулу для вычисления дисперсии выборки. Дисперсия является мерой разброса значений некоторой величины. Чем ближе значение дисперсии к нулю, тем ближе значения сгруппированы друг к другу. Работая с выборкой значений, используйте следующую формулу для вычисления дисперсии:
- s 2 {\displaystyle s^{2}} = ∑[( x i {\displaystyle x_{i}} - x̅) 2 {\displaystyle ^{2}} ] / (n - 1)
- s 2 {\displaystyle s^{2}} – это дисперсия. Дисперсия измеряется в квадратных единицах измерения.
- x i {\displaystyle x_{i}} – каждое значение в выборке.
- x i {\displaystyle x_{i}} нужно вычесть x̅, возвести в квадрат, а затем сложить полученные результаты.
- x̅ – выборочное среднее (среднее значение выборки).
- n – количество значений в выборке.
-
Вычислите среднее значение выборки. Оно обозначается как x̅. Среднее значение выборки вычисляется как обычное среднее арифметическое: сложите все значения в выборке, а затем полученный результат разделите на количество значений в выборке.
- В нашем примере сложите значения в выборке: 15 + 17 + 23 + 7 + 9 + 13 = 84
Теперь результат разделите на количество значений в выборке (в нашем примере их 6): 84 ÷ 6 = 14.
Выборочное среднее x̅ = 14. - Выборочное среднее – это центральное значение, вокруг которого распределены значения в выборке. Если значения в выборке группируются вокруг выборочного среднего, то дисперсия мала; в противном случае дисперсия велика.
- В нашем примере сложите значения в выборке: 15 + 17 + 23 + 7 + 9 + 13 = 84
-
Вычтите выборочное среднее из каждого значения в выборке. Теперь вычислите разность x i {\displaystyle x_{i}} - x̅, где x i {\displaystyle x_{i}} – каждое значение в выборке. Каждый полученный результат свидетельствует о мере отклонения конкретного значения от выборочного среднего, то есть как далеко это значение находится от среднего значения выборки.
- В нашем примере:
x 1 {\displaystyle x_{1}} - x̅ = 17 - 14 = 3
x 2 {\displaystyle x_{2}} - x̅ = 15 - 14 = 1
x 3 {\displaystyle x_{3}} - x̅ = 23 - 14 = 9
x 4 {\displaystyle x_{4}} - x̅ = 7 - 14 = -7
x 5 {\displaystyle x_{5}} - x̅ = 9 - 14 = -5
x 6 {\displaystyle x_{6}} - x̅ = 13 - 14 = -1 - Правильность полученных результатов легко проверить, так как их сумма должна равняться нулю. Это связано с определением среднего значения, так как отрицательные значения (расстояния от среднего значения до меньших значений) полностью компенсируются положительными значениями (расстояниями от среднего значения до больших значений).
- В нашем примере:
-
Как отмечалось выше, сумма разностей x i {\displaystyle x_{i}} - x̅ должна быть равна нулю. Это означает, что средняя дисперсия всегда равна нулю, что не дает никакого представления о разбросе значений некоторой величины. Для решения этой проблемы возведите в квадрат каждую разность x i {\displaystyle x_{i}} - x̅. Это приведет к тому, что вы получите только положительные числа, которые при сложении никогда не дадут 0.
- В нашем примере:
( x 1 {\displaystyle x_{1}} - x̅) 2 = 3 2 = 9 {\displaystyle ^{2}=3^{2}=9}
(x 2 {\displaystyle (x_{2}} - x̅) 2 = 1 2 = 1 {\displaystyle ^{2}=1^{2}=1}
9 2 = 81
(-7) 2 = 49
(-5) 2 = 25
(-1) 2 = 1 - Вы нашли квадрат разности - x̅) 2 {\displaystyle ^{2}} для каждого значения в выборке.
- В нашем примере:
-
Вычислите сумму квадратов разностей. То есть найдите ту часть формулы, которая записывается так: ∑[( x i {\displaystyle x_{i}} - x̅) 2 {\displaystyle ^{2}} ]. Здесь знак Σ означает сумму квадратов разностей для каждого значения x i {\displaystyle x_{i}} в выборке. Вы уже нашли квадраты разностей (x i {\displaystyle (x_{i}} - x̅) 2 {\displaystyle ^{2}} для каждого значения x i {\displaystyle x_{i}} в выборке; теперь просто сложите эти квадраты.
- В нашем примере: 9 + 1 + 81 + 49 + 25 + 1 = 166 .
-
Полученный результат разделите на n - 1, где n – количество значений в выборке. Некоторое время назад для вычисления дисперсии выборки статистики делили результат просто на n; в этом случае вы получите среднее значение квадрата дисперсии, которое идеально подходит для описания дисперсии данной выборки. Но помните, что любая выборка – это лишь небольшая часть генеральной совокупности значений. Если взять другую выборку и выполнить такие же вычисления, вы получите другой результат. Как выяснилось, деление на n - 1 (а не просто на n) дает более точную оценку дисперсии генеральной совокупности, в чем вы и заинтересованы. Деление на n – 1 стало общепринятым, поэтому оно включено в формулу для вычисления дисперсии выборки.
- В нашем примере выборка включает 6 значений, то есть n = 6.
Дисперсия выборки = s 2 = 166 6 − 1 = {\displaystyle s^{2}={\frac {166}{6-1}}=} 33,2
- В нашем примере выборка включает 6 значений, то есть n = 6.
-
Отличие дисперсии от стандартного отклонения. Заметьте, что в формуле присутствует показатель степени, поэтому дисперсия измеряется в квадратных единицах измерения анализируемой величины. Иногда такой величиной довольно сложно оперировать; в таких случаях пользуются стандартным отклонением, которое равно квадратному корню из дисперсии. Именно поэтому дисперсия выборки обозначается как s 2 {\displaystyle s^{2}} , а стандартное отклонение выборки – как s {\displaystyle s} .
- В нашем примере стандартное отклонение выборки: s = √33,2 = 5,76.
Вычисление дисперсии совокупности
-
Проанализируйте некоторую совокупность значений. Совокупность включает в себя все значения рассматриваемой величины. Например, если вы изучаете возраст жителей Ленинградской области, то совокупность включает возраст всех жителей этой области. В случае работы с совокупностью рекомендуется создать таблицу и внести в нее значения совокупности. Рассмотрим следующий пример:
- В некоторой комнате находятся 6 аквариумов. В каждом аквариуме обитает следующее количество рыб:
x 1 = 5 {\displaystyle x_{1}=5}
x 2 = 5 {\displaystyle x_{2}=5}
x 3 = 8 {\displaystyle x_{3}=8}
x 4 = 12 {\displaystyle x_{4}=12}
x 5 = 15 {\displaystyle x_{5}=15}
x 6 = 18 {\displaystyle x_{6}=18}
- В некоторой комнате находятся 6 аквариумов. В каждом аквариуме обитает следующее количество рыб:
-
Запишите формулу для вычисления дисперсии генеральной совокупности. Так как в совокупность входят все значения некоторой величины, то приведенная ниже формула позволяет получить точное значение дисперсии совокупности. Для того чтобы отличить дисперсию совокупности от дисперсии выборки (значение которой является лишь оценочным), статистики используют различные переменные:
- σ 2 {\displaystyle ^{2}} = (∑( x i {\displaystyle x_{i}} - μ) 2 {\displaystyle ^{2}} ) / n
- σ 2 {\displaystyle ^{2}} – дисперсия совокупности (читается как «сигма в квадрате»). Дисперсия измеряется в квадратных единицах измерения.
- x i {\displaystyle x_{i}} – каждое значение в совокупности.
- Σ – знак суммы. То есть из каждого значения x i {\displaystyle x_{i}} нужно вычесть μ, возвести в квадрат, а затем сложить полученные результаты.
- μ – среднее значение совокупности.
- n – количество значений в генеральной совокупности.
-
Вычислите среднее значение совокупности. При работе с генеральной совокупностью ее среднее значение обозначается как μ (мю). Среднее значение совокупности вычисляется как обычное среднее арифметическое: сложите все значения в генеральной совокупности, а затем полученный результат разделите на количество значений в генеральной совокупности.
- Имейте в виду, что средние величины не всегда вычисляются как среднее арифметическое.
- В нашем примере среднее значение совокупности: μ = 5 + 5 + 8 + 12 + 15 + 18 6 {\displaystyle {\frac {5+5+8+12+15+18}{6}}} = 10,5
-
Вычтите среднее значение совокупности из каждого значения в генеральной совокупности. Чем ближе значение разности к нулю, тем ближе конкретное значение к среднему значению совокупности. Найдите разность между каждым значением в совокупности и ее средним значением, и вы получите первое представление о распределении значений.
- В нашем примере:
x 1 {\displaystyle x_{1}} - μ = 5 - 10,5 = -5,5
x 2 {\displaystyle x_{2}} - μ = 5 - 10,5 = -5,5
x 3 {\displaystyle x_{3}} - μ = 8 - 10,5 = -2,5
x 4 {\displaystyle x_{4}} - μ = 12 - 10,5 = 1,5
x 5 {\displaystyle x_{5}} - μ = 15 - 10,5 = 4,5
x 6 {\displaystyle x_{6}} - μ = 18 - 10,5 = 7,5
- В нашем примере:
-
Возведите в квадрат каждый полученный результат. Значения разностей будут как положительными, так и отрицательными; если нанести эти значения на числовую прямую, то они будут лежать справа и слева от среднего значения совокупности. Это не годится для вычисления дисперсии, так как положительные и отрицательные числа компенсируют друг друга. Поэтому возведите в квадрат каждую разность, чтобы получить исключительно положительные числа.
- В нашем примере:
( x i {\displaystyle x_{i}} - μ) 2 {\displaystyle ^{2}} для каждого значения совокупности (от i = 1 до i = 6):
(-5,5) 2 {\displaystyle ^{2}} = 30,25
(-5,5) 2 {\displaystyle ^{2}} , где x n {\displaystyle x_{n}} – последнее значение в генеральной совокупности. - Для вычисления среднего значения полученных результатов нужно найти их сумму и разделить ее на n:(( x 1 {\displaystyle x_{1}} - μ) 2 {\displaystyle ^{2}} + ( x 2 {\displaystyle x_{2}} - μ) 2 {\displaystyle ^{2}} + ... + ( x n {\displaystyle x_{n}} - μ) 2 {\displaystyle ^{2}} ) / n
- Теперь запишем приведенное объяснение с использованием переменных: (∑( x i {\displaystyle x_{i}} - μ) 2 {\displaystyle ^{2}} ) / n и получим формулу для вычисления дисперсии совокупности.
- В нашем примере:
Часто в статистике при анализе какого-либо явления или процесса необходимо учитывать не только информацию о средних уровнях исследуемых показателей, но и разброс или вариацию значений отдельных единиц , которая является важной характеристикой изучаемой совокупности.
В наибольшей степени вариации подвержены курсы акций, объемы спроса и предложения, процентные ставки в разные периоды времени и в разных местах.
Основными показателями, характеризующими вариацию , являются размах, дисперсия, среднее квадратическое отклонение и коэффициент вариации.
Размах вариации представляет собой разность максимального и минимального значений признака: R = Xmax – Xmin . Недостатком данного показателя является то, что он оценивает только границы варьирования признака и не отражает его колеблемость внутри этих границ.
Дисперсия лишена этого недостатка. Она рассчитывается как средний квадрат отклонений значений признака от их средней величины:
Упрощенный способ расчета дисперсии осуществляется с помощью следующих формул (простой и взвешенной):
Примеры применения данных формул представлены в задачах 1 и 2.
Широко распространенным на практике показателем является среднее квадратическое отклонение :
Среднее квадратическое отклонение определяется как квадратный корень из дисперсии и имеет ту же размеренность, что и изучаемый признак.
Рассмотренные показатели позволяют получить абсолютное значение вариации, т.е. оценивают ее в единицах измерения исследуемого признака. В отличие от них, коэффициент вариации измеряет колеблемость в относительном выражении - относительно среднего уровня, что во многих случаях является предпочтительнее.
Формула для расчета коэффициента вариации.
Примеры решения задач по теме «Показатели вариации в статистике»
Задача 1 . При изучении влияния рекламы на размер среднемесячного вклада в банках района обследовано 2 банка. Получены следующие результаты:
Определить:
1) для каждого банка: а) средний размер вклада за месяц; б) дисперсию вклада;
2) средний размер вклада за месяц для двух банков вместе;
3) Дисперсию вклада для 2-х банков, зависящую от рекламы;
4) Дисперсию вклада для 2-х банков, зависящую от всех факторов, кроме рекламы;
5) Общую дисперсию используя правило сложения;
6) Коэффициент детерминации;
7) Корреляционное отношение.
Решение
1) Составим расчетную таблицу для банка с рекламой . Для определения среднего размера вклада за месяц найдем середины интервалов. При этом величина открытого интервала (первого) условно приравнивается к величине интервала, примыкающего к нему (второго).
Средний размер вклада найдем по формуле средней арифметической взвешенной:
29 000/50 = 580 руб.
Дисперсию вклада найдем по формуле:
23 400/50 = 468
Аналогичные действия произведем для банка без рекламы :
2) Найдем средний размер вклада для двух банков вместе. Хср =(580×50+542,8×50)/100 = 561,4 руб.
3) Дисперсию вклада, для двух банков, зависящую от рекламы найдем по формуле: σ 2 =pq (формула дисперсии альтернативного признака). Здесь р=0,5 – доля факторов, зависящих от рекламы; q=1-0,5, тогда σ 2 =0,5*0,5=0,25.
4) Поскольку доля остальных факторов равна 0,5, то дисперсия вклада для двух банков, зависящая от всех факторов кроме рекламы тоже 0,25.
5) Определим общую дисперсию, используя правило сложения.
= (468*50+636,16*50)/100=552,08
= [(580-561,4)250+(542,8-561,4)250] / 100= 34 596/ 100=345,96
σ 2 = σ 2 факт + σ 2 ост = 552,08+345,96 = 898,04
6) Коэффициент детерминации η 2 = σ 2 факт / σ 2 = 345,96/898,04 = 0,39 = 39% - размер вклада на 39% зависит от рекламы.
7) Эмпирическое корреляционное отношение η = √η 2 = √0,39 = 0,62 – связь достаточно тесная.
Задача 2 . Имеется группировка предприятий по величине товарной продукции:
Определить: 1) дисперсию величины товарной продукции; 2) среднее квадратическое отклонение; 3) коэффициент вариации.
Решение
1) По условию представлен интервальный ряд распределения. Его необходимо выразить дискретно, то есть найти середину интервала (х"). В группах закрытых интервалов середину найдем по простой средней арифметической. В группах с верхней границей - как разность между этой верхней границей и половиной размера следующего за ним интервала (200-(400-200):2=100).
В группах с нижней границей – суммой этой нижней границы и половины размера предыдущего интервала (800+(800-600):2=900).
Расчет средней величины товарной продукции делаем по формуле:
Хср = k×((Σ((х"-a):k)×f):Σf)+a. Здесь а=500 - размер варианта при наибольшей частоте, k=600-400=200 - размер интервала при наибольшей частоте. Результат поместим в таблицу:
Итак, средняя величина товарной продукции за изучаемый период в целом равна Хср = (-5:37)×200+500=472,97 тыс. руб.
2) Дисперсию найдем по следующей формуле:
σ 2 = (33/37)*2002-(472,97-500)2 = 35 675,67-730,62 = 34 945,05
3) среднее квадратическое отклонение: σ = ±√σ 2 = ±√34 945,05 ≈ ±186,94 тыс. руб.
4) коэффициент вариации: V = (σ /Хср)*100 = (186,94 / 472,97)*100 = 39,52%
 .
.
Обратно,
если -
неотрицательная п.в. функция, такая
что  ,
то существует абсолютно непрерывная
вероятностная мера на такая,
что является
её плотностью.
,
то существует абсолютно непрерывная
вероятностная мера на такая,
что является
её плотностью.
Замена меры в интеграле Лебега:
 ,
,
где любая борелевская функция, интегрируемая относительно вероятностной меры .
Дисперсия, виды и свойства дисперсии Понятие дисперсии
Дисперсия в статистике находится как среднее квадратическое отклонение индивидуальных значений признака в квадрате от средней арифметической. В зависимости от исходных данных она определяется по формулам простой и взвешенной дисперсий:
1. Простая дисперсия (для несгруппированных данных) вычисляется по формуле:
![]()
2. Взвешенная дисперсия (для вариационного ряда):

где n - частота (повторяемость фактора Х)
Пример нахождения дисперсии
На данной странице описан стандартный пример нахождения дисперсии, также Вы можете посмотреть другие задачи на её нахождение
Пример 1. Определение групповой, средней из групповой, межгрупповой и общей дисперсии
Пример 2. Нахождение дисперсии и коэффициента вариации в группировочной таблице
Пример 3. Нахождение дисперсии в дискретном ряду
Пример 4. Имеются следующие данные по группе из 20 студентов заочного отделения. Нужно построить интервальный ряд распределения признака, рассчитать среднее значение признака и изучить его дисперсию

Построим интервальную группировку. Определим размах интервала по формуле:
![]()
где X max– максимальное значение группировочного признака; X min–минимальное значение группировочного признака; n – количество интервалов:
Принимаем n=5. Шаг равен: h = (192 - 159)/ 5 = 6,6
Составим интервальную группировку

Для дальнейших расчетов построим вспомогательную таблицу:

X"i– середина интервала. (например середина интервала 159 – 165,6 = 162,3)
Среднюю величину роста студентов определим по формуле средней арифметической взвешенной:

Определим дисперсию по формуле:
Формулу можно преобразовать так:

Из этой формулы следует, что дисперсия равна разности средней из квадратов вариантов и квадрата и средней.
Дисперсия в вариационных рядах с равными интервалами по способу моментов может быть рассчитана следующим способом при использовании второго свойства дисперсии (разделив все варианты на величину интервала). Определении дисперсии , вычисленной по способу моментов, по следующей формуле менее трудоемок:

где i - величина интервала; А - условный ноль, в качестве которого удобно использовать середину интервала, обладающего наибольшей частотой; m1 - квадрат момента первого порядка; m2 - момент второго порядка
Дисперсия альтернативного признака (если в статистической совокупности признак изменяется так, что имеются только два взаимно исключающих друг друга варианта, то такая изменчивость называется альтернативной) может быть вычислена по формуле:

Подставляя в данную формулу дисперсии q =1- р, получаем:

Виды дисперсии
Общая дисперсия измеряет вариацию признака по всей совокупности в целом под влиянием всех факторов, обуславливающих эту вариацию. Она равняется среднему квадрату отклонений отдельных значений признака х от общего среднего значения х и может быть определена как простая дисперсия или взвешенная дисперсия.
Внутригрупповая дисперсия характеризует случайную вариацию, т.е. часть вариации, которая обусловлена влиянием неучтенных факторов и не зависящую от признака-фактора, положенного в основание группировки. Такая дисперсия равна среднему квадрату отклонений отдельных значений признака внутри группы X от средней арифметической группы и может быть вычислена как простая дисперсия или как взвешенная дисперсия.
Таким образом, внутригрупповая дисперсия измеряет вариацию признака внутри группы и определяется по формуле:

где хi - групповая средняя; ni - число единиц в группе.
Например, внутригрупповые дисперсии, которые надо определить в задаче изучения влияния квалификации рабочих на уровень производительности труда в цехе показывают вариации выработки в каждой группе, вызванные всеми возможными факторами (техническое состояние оборудования, обеспеченность инструментами и материалами, возраст рабочих, интенсивность труда и т.д.), кроме отличий в квалификационном разряде (внутри группы все рабочие имеют одну и ту же квалификацию).
Средняя из внутри групповых дисперсий отражает случайную вариацию, т. е. ту часть вариации, которая происходила под влиянием всех прочих факторов, за исключением фактора группировки. Она рассчитывается по формуле:

Межгрупповая дисперсия характеризует систематическую вариацию результативного признака, которая обусловлена влиянием признака-фактора, положенного в основание группировки. Она равняется среднему квадрату отклонений групповых средних от общей средней. Межгрупповая дисперсия рассчитывается по формуле:

Вариационный размах (или размах вариации) - это разница между максимальным и минимальным значениями признака:
В нашем примере размах вариации сменной выработки рабочих составляет: в первой бригаде R=105-95=10 дет., во второй бригаде R=125-75=50 дет. (в 5 раз больше). Это говорит о том, что выработка 1-й бригады более «устойчива», но резервов роста выработки больше у второй бригады, т.к. в случае достижения всеми рабочими максимальной для этой бригады выработки, ею может быть изготовлено 3*125=375 деталей, а в 1-й бригаде только 105*3=315 деталей.
Если крайние значения признака не типичны для совокупности, то используют квартильный или децильный размахи. Квартильный размах RQ= Q3-Q1 охватывает 50% объема совокупности, децильный размах первый RD1 = D9-D1охватывает 80% данных, второй децильный размах RD2= D8-D2 – 60 %.
Недостатком показателя вариационного размаха является, но что его величина не отражает все колебания признака.
Простейшим обобщающим показателем, отражающим все колебания признака, является среднее линейное отклонение
, представляющее собой среднюю арифметическую абсолютных отклонений отдельных вариант от их средней величины:
,
для сгруппированных данных ![]() ,
,
где хi – значение признака в дискретном ряду или середина интервала в интервальном распределении.
В вышеприведенных формулах разности в числителе взяты по модулю, иначе, согласно свойству средней арифметической, числитель всегда будет равен нулю. Поэтому среднее линейное отклонение в статистической практике применяют редко, только в тех случаях, когда суммирование показателей без учета знака имеет экономический смысл. С его помощью, например, анализируется состав работающих, рентабельность производства, оборот внешней торговли.
Дисперсия признака
– это средний квадрат отклонений вариант от их средней величины:
простая дисперсия![]() ,
,
взвешенная дисперсия .
.
Формулу для расчета дисперсии можно упростить:
Таким образом, дисперсия равна разности средней из квадратов вариант и квадрата средней из вариант совокупности: .
.
Однако, вследствие суммирования квадратов отклонений дисперсия дает искаженное представление об отклонениях, поэтому ее на основе рассчитывают среднее квадратическое отклонение
, которое показывает, на сколько в среднем отклоняются конкретные варианты признака от их среднего значения. Вычисляется путем извлечения квадратного корня из дисперсии:
для несгруппированных данных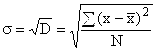 ,
,
для вариационного ряда
Чем меньше значение дисперсии и среднего квадратического отклонения, тем однороднее совокупность, тем более надежной (типичной) будет средняя величина.
Среднее линейное и среднее квадратичное отклонение - именованные числа, т. е. выражаются в единицах измерения признака, идентичны по содержанию и близки по значению.
Рассчитывать абсолютные показатели вариации рекомендуется с помощью таблиц.
Таблица 3 – Расчет характеристик вариации (на примере срока данных о сменной выработке рабочих бригады)
Число рабочих, |
Середина интервала, |
Расчетные значения |
|||||
Итого: |
|||||||
Среднесменная выработка рабочих:![]()
Среднее линейное отклонение:![]()
Дисперсия выработки: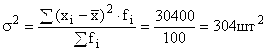
Среднее квадратическое отклонение выработки отдельных рабочих от средней выработки:
.
1 Расчет дисперсии способом моментов
Вычисление дисперсий связано с громоздкими расчетами (особенно если средняя величина выражена большим числом с несколькими десятичными знаками). Расчеты можно упростить, если использовать упрощенную формулу и свойства дисперсии.
Дисперсия обладает следующими свойствами:
- если все значения признака уменьшить или увеличить на одну и ту же величину А, то дисперсия от этого не уменьшится:
 ,
,
 , то или
, то или 
Используя свойства дисперсии и сначала уменьшив все варианты совокупности на величину А, а затем разделив на величину интервала h, получим формулу вычисления дисперсии в вариационных рядах с равными интервалами способом моментов:
 ,
,
где – дисперсия, исчисленная по способу моментов;
h – величина интервала вариационного ряда;
– новые (преобразованные) значения вариант;
А– постоянная величина, в качестве которой используют середину интервала, обладающего наибольшей частотой; либо вариант, имеющий наибольшую частоту; 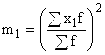 – квадрат момента первого порядка;
– квадрат момента первого порядка;
– момент второго порядка.
Выполним расчет дисперсии способом моментов на основе данных о сменной выработке рабочих бригады.
Таблица 4 – Расчет дисперсии по способу моментов
Группы рабочих по выработке, шт. |
Число рабочих, |
Середина интервала, |
Расчетные значения |
||
Порядок расчета:


- рассчитываем дисперсию:
2 Расчет дисперсии альтернативного признака
Среди признаков, изучаемых статистикой, есть и такие, которым свойственны лишь два взаимно исключающих значения. Это альтернативные признаки. Им придается соответственно два количественных значения: варианты 1 и 0. Частостью варианты 1, которая обозначается p, является доля единиц, обладающих данным признаком. Разность 1-р=q является частостью варианты 0. Таким образом,
хi |
|
Средняя арифметическая альтернативного признака![]() , т. к. p+q=1.
, т. к. p+q=1.
Дисперсия альтернативного признака
, т.к. 1-р=q
Таким образом, дисперсия альтернативного признака равна произведению доли единиц, обладающих данным признаком, и доли единиц, не обладающих этим признаком.
Если значения 1 и 0 встречаются одинаково часто, т. е. p=q, дисперсия достигает своего максимума pq=0,25.
Дисперсия альтернативного признака используется в выборочных обследованиях, например, качества продукции.
3 Межгрупповая дисперсия. Правило сложения дисперсий
Дисперсия, в отличие от других характеристик вариации, является аддитивной величиной. То есть в совокупности, которая разделена на группы по факторному признаку х, дисперсия результативного признака y может быть разложена на дисперсию в каждой группе (внутригрупповую) и дисперсию между группами (межгрупповую). Тогда, наряду с изучением вариации признака по всей совокупности в целом, становится возможным изучение вариации в каждой группе, а также между этими группами.
Общая дисперсия
измеряет вариацию признака у
по всей совокупности под влиянием всех факторов, вызвавших эту вариацию (отклонения). Она равна среднему квадрату отклонений отдельных значений признака у
от общей средней и может быть вычислена как простая или взвешенная дисперсия.
Межгрупповая дисперсия
характеризует вариацию результативного признака у
, вызванную влиянием признака-фактора х
, положенного в основу группировки. Она характеризует вариацию групповых средних и равна среднему квадрату отклонений групповых средних от общей средней : ,
,
где – средняя арифметическая i-той группы;
– численность единиц в i-той группе (частота i-той группы);
– общая средняя совокупности.
Внутригрупповая дисперсия
отражает случайную вариацию, т. е. ту часть вариации, которая вызвана влиянием неучтенных факторов и не зависит от признака-фактора, положенного в основу группировки. Она характеризует вариацию индивидуальных значений относительно групповых средних, равна среднему квадрату отклонений отдельных значений признака у
внутри группы от средней арифметической этой группы (групповой средней) и вычисляется как простая или взвешенная дисперсия для каждой группы: ![]() или
или ![]() ,
,
где – число единиц в группе.
На основании внутригрупповых дисперсий по каждой группе можно определить общую среднюю из внутригрупповых дисперсий
:
.
Взаимосвязь между тремя дисперсиями получила название правила сложения дисперсий
, согласно которому общая дисперсия равна сумме межгрупповой дисперсии и средней из внутригрупповых дисперсий:
Пример
. При изучении влияния тарифного разряда (квалификации) рабочих на уровень производительности их труда получены следующие данные.
Таблица 5 – Распределение рабочих по среднечасовой выработке.
№ п/п |
Рабочие 4-го разряда |
Рабочие 5-го разряда |
|||||
Выработка |
Выработка |
||||||
1 |
7 |
7-10=-3 |
9 |
1 |
14 |
14-15=-1 |
1 |
В данном примере рабочие разделены на две группы по факторному признаку х
– квалификации, которая характеризуется их разрядом. Результативный признак – выработка – варьируется как под его влиянием (межгрупповая вариация), так и за счет других случайных факторов (внутригрупповая вариация). Задача заключается в измерении этих вариаций с помощью трех дисперсий: общей, межгрупповой и внутригрупповой.
Эмпирический коэффициент детерминации показывает долю вариации результативного признака у
под влиянием факторного признака х
. Остальная часть общей вариации у
вызвана изменением прочих факторов.
В примере эмпирический коэффициент детерминации равен:![]() или 66,7 %,
или 66,7 %,
Это означает, что на 66,7% вариация производительности труда рабочих обусловлена различиями в квалификации, а на 33,3% – влиянием прочих факторов.
Эмпирическое корреляционное отношение
показывает тесноту связи между группировочным и результативными признаками. Рассчитывается как корень квадратный из эмпирического коэффициента детерминации:
Эмпирическое корреляционное отношение , как и , может принимать значения от 0 до 1.
Если связь отсутствует, то =0. В этом случае =0, то есть групповые средние равны между собой и межгрупповой вариации нет. Значит группировочный признак – фактор не влияет на образование общей вариации.
Если связь функциональная, то =1. В этом случае дисперсия групповых средних равна общей дисперсии (), то есть внутригрупповой вариации нет. Это означает, что группировочный признак полностью определяет вариацию изучаемого результативного признака.
Чем ближе значение корреляционного отношения к единице, тем теснее, ближе к функциональной зависимости связь между признаками.
Для качественной оценки тесноты связи между признаками пользуются соотношениями Чэддока.
В примере ![]() , что свидетельствует о тесной связи между производительностью труда рабочих и их квалификацией.
, что свидетельствует о тесной связи между производительностью труда рабочих и их квалификацией.